Retos y mejores prácticas en aplicaciones de Inteligencia Artificial (IA)

¿Con qué rapidez se mueven las tecnologías de Machine Learning (ML) e inteligencia artificial (IA)? Tomemos el caso de AlphaGo. En 2015, gracias al ML, se convirtió en el primer programa informático en vencer a un jugador profesional de Go (considerado uno de los juegos de estrategia más complejos que existen). En 2017, AlphaGo Master, la siguiente edición del programa, venció al jugador número uno del mundo en ese momento. Ambas versiones demostraron que el ML podría superar el desempeño humano.
Muchas personas se emocionan y asocian ML/AI a todos los aspectos de la actividad humana, afirmando que estas tecnologías reemplazarán la mayoría de los trabajos humanos, incluso los profesionales.
Sin embargo, existen muchos desafíos al aplicar ML a aplicaciones del mundo real. Imagina si AlphaGo solo pudiera ver una parte del tablero de Go, o si hubiera reglas ocultas no definidas por adelantado. En el mundo real, las aplicaciones no suelen definirse con tanta claridad como las piedras blancas o negras del tablero Go. Y en el espacio industrial, el entorno es infinitamente más complicado, donde el comportamiento humano y las operaciones de las máquinas están enredados con procesos físicos, químicos y biológicos en equipos mecánicos, eléctricos y electrónicos. Introduce desafíos específicos para las aplicaciones industriales de IA desde la perspectiva de los algoritmos y los datos.

Desafíos del algoritmo
Una analogía: AI/ML para la revolución digital es como el motor de vapor y gas para la revolución industrial. Imagina que cada algoritmo de IA/ML es un motor. Necesita diferentes tipos de motores para diferentes aplicaciones; No hay una talla para todos. Por ejemplo, un motor diseñado para un Ferrari no es el más adecuado para un tractor usado en una granja.
Requisito de alta fidelidad: existen algunos requisitos específicos para el motor de IA para aplicaciones industriales. El más crítico es la gran expectativa en torno a la sensibilidad y la especificidad. Tomemos, por ejemplo, el sistema de recomendación de compras online o un sistema de recomendación de películas. Si encuentra un par de elementos que te gustaron en las recomendaciones enumeradas, puede dar a pensar que esta funcionalidad impulsada por IA es sorprendente. Pero en un sistema de predicción de fallos de máquinas, perder un fallo probablemente hará que se cuestione la confiabilidad del sistema, a pesar de que detecta el otro 99% de las fallos. ¿Por qué? Una predicción falsa en un entorno industrial puede causar pérdidas de producción, costos laborales y retrasos en el proyecto, o incluso una falla catastrófica, que podría causar millones de dólares en daños o pérdida de producción, impactos ambientales o lesiones graves.
Requisito de resultado explicable/procesable: debido a lo mucho que está en juego, los ingenieros y técnicos que han estado trabajando en el campo durante muchos años pueden no confiar en las recomendaciones de la caja negra si no pueden explicar cómo se hicieron las predicciones porque hay consecuencias en el mundo real para cada acción realizada (o no realizada). Para generar confianza, la salida de la IA debe ser explicable y procesable.
Requisito de límite de dominio: AI/ML debe proporcionar información útil dentro de los límites del conocimiento del dominio. AI/ML se basan en datos y los datos se recopilan de sistemas físicos que siguen las leyes físicas. A menudo escucho a los expertos en el dominio decir: "No me digas algo que ya sepa o algo que no tenga sentido en mi dominio o que infrinja determinadas normas, éticas o directrices".
Desafíos de datos
Si pensamos en AI/ML como un motor de gas, entonces los datos son la energía para impulsar los algoritmos de AI/ML. Poseer datos es más valioso y crucial que poseer algoritmos, pero existen muchos desafíos específicos asociados con los datos en el espacio industrial.
Los motores no pueden consumir petróleo crudo, por lo que es necesaria una refinería de petróleo para transformar el petróleo crudo en gasolina limpia. Los datos industriales tienen que pasar por un proceso similar de refinamiento o limpieza para ser consumidos por los algoritmos ML. Durante este proceso, el conocimiento del dominio es la clave, y es ese conocimiento el que decide cómo se procesan los datos.
Precisamente, el módulo “Troubleshooter” del software CSense es una herramienta excelente para este análisis y depuración de los datos sucos o crudos. Se trata de una potente herramienta para un análisis offline de la información histórica. Además de aportar medios para destilar conocimiento de los datos, permite sentar las bases para etapas más avanzadas de creación de modelos, simulaciones o predicciones en tiempo real.
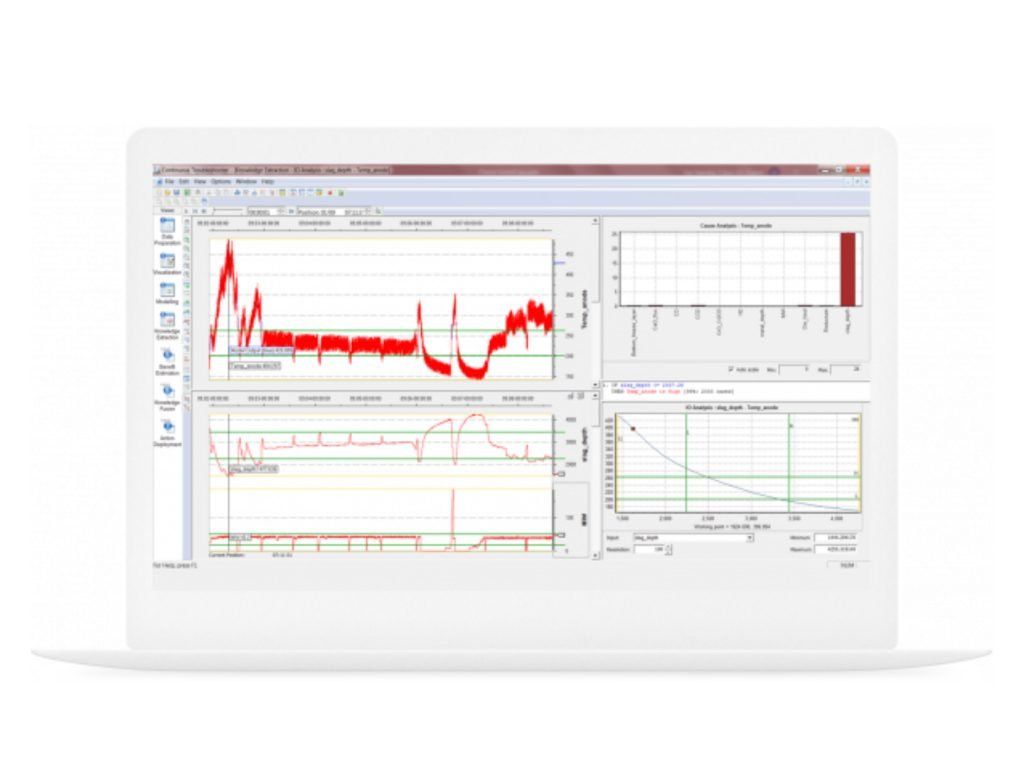
Datos sucios: el primero y más importante es el problema de los "datos sucios", el dolor de cabeza de todo científico de datos. Esto no es exclusivo de las aplicaciones industriales, pero es más complejo que los datos faltantes o redundantes. Los datos se recopilan con mucho ruido (los datos están corruptos o distorsionados, o tienen una relación señal/ruido baja u otra información sin sentido) y varían de una fuente a otra. Es una de las partes más desafiantes del proceso debido a problemas ambientales, restricciones presupuestarias, factores humanos y otras limitaciones.
Desequilibrio de clases: para que la mayoría de los algoritmos ML funcionen, deben enseñarse con ejemplos; esto se llama datos de entrenamiento. Los datos de entrenamiento incluyen todos los patrones posibles con resultados claramente etiquetados. Para la detección de fallos en aplicaciones industriales, no existen estándares de oro, y los patrones normales/defectuosos generalmente dependen del contexto. Las razones de fallo de la máquina continúan evolucionando y no existe un límite en blanco y negro para crear distinciones claras en cada algoritmo. Además, los fallos son raros en el entorno industrial debido a todos los diseños y características de seguridad. Esto tiene dos consecuencias: (1) no hay suficientes patrones de fallo en su conjunto de datos de entrenamiento y (2) no todas los fallos tienen datos.
Etiquetado de datos: incluso si tienes suficientes datos sin procesar, crear un conjunto de datos de entrenamiento etiquetado para algoritmos de Machine Learning sigue siendo un desafío. Para que los algoritmos de ML aprendan, el conjunto de datos debe categorizarse en una clase buena/mala o en varias clases. Sin embargo, no hay muchos expertos industriales disponibles para encontrar patrones de falla en los datos y son costosos. No todas las empresas tienen la capacidad como General Electric (GE) para tener un equipo de expertos con décadas de experiencia en la industria.
Conocimiento tácito: otro gran desafío es la comprensión del contexto y la situación. No todo se registra en un formato de datos estandarizado. Hay información de contexto, conocimiento tácito e información específica del dominio. Por ejemplo, en los registros de mantenimiento de los sistemas CMMS, los ingenieros pueden usar jerga y abreviaturas para registrar modos de fallo, síntomas y acciones de reparación. Sin el conocimiento adecuado del dominio, es posible que no se comprenda completamente la información de un registro de mantenimiento.

En resumen, los conjuntos de datos industriales y los requisitos industriales plantean desafíos para la IA/ML. El éxito depende de comprender estos desafíos específicos y las mejores prácticas asociadas para abordar los desafíos del diseño de aplicaciones de IA industrial.
Artículo original de Mark Hu, Director de Data & Analytics en GE Digital
¿Te interesa este tema?
Habla con nuestro equipo de expertos en automatización industrial.
Contactar con un experto